MySQL로 배우는 데이터베이스 개론과 실습 (1)
1. 데이터베이스 시스템
# 데이터베이스란
- 논리적으로 연관된 데이터를 모아 구조적으로 통합해 놓은 것
- DB 시스템은 데이터의 검색(search)과 변경(modification) 작업이 메인
- DB 시스템은 검색과 변경 빈도에 따라 크게 네 가지 유형으로 나뉨

# 데이터베이스 개념
- DB란 쉽게 말해 데이터의 집합인데, 이 개념을 구체적으로 네 가지로 쪼갤 수 있음
- 통합된 데이터(integrated data) : 여러 곳에서 사용하던 데이터를 통합한 것
- 저장된 데이터(stored data) : 단순 문서보관이 아닌, 디스크나 테이프 같은 컴퓨터 저장 장치에 저장된 데이터를 의미
- 운영 데이터(operational data) : 조직(회사, ... )의 목적을 위해 사용되는 데이터
- 공용데이터(shared data) : 한 사람 / 한 업무만을 위한 데이터가 아닌, 공용으로 사용되는 데이터를 의미
# 데이터베이스 특징
- 실시간 접근 가능(real-time accessibility)
- 지속적 변화(continuous evolution)
- 동시 공유 가능(concurrent sharing)
- 내용 참조 가능(content reference) : DB에 저장된 데이터는 물리적 위치가 아닌, 데이터 값을 사용해 참조함
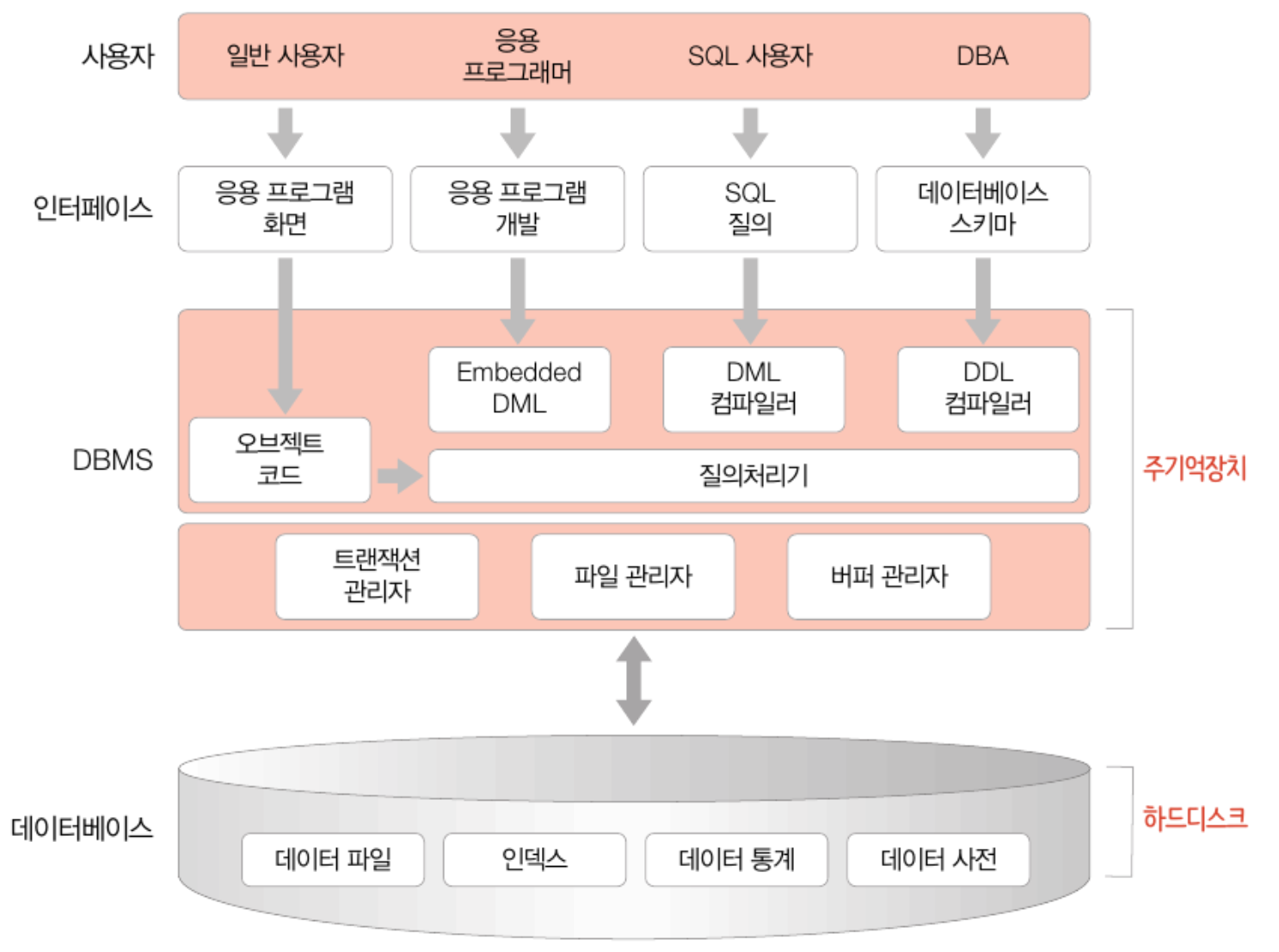
# 데이터베이스 시스템 구성
- DB시스템은 관리 시스템, 데이터베이스, 데이터 모델 세 가지로 구성됨
- 관리 시스템(DBMS) : 데이터를 관리하는 소프트웨어. 사용자와 데이터베이스를 연결해줌
- 데이터베이스 : 데이터를 모아 둔 토대. 컴퓨터 내부의 하드디스크에 물리적으로 저장됨
- 데이터 모델 : 논리적 개념으로, 데이터가 저장되는 기법에 관한 내용
- 추가 구성 요소 : 데이터베이스 언어, 데이터베이스 사용자

# 데이터베이스 언어
- DB시스템은 DB전용 언어인 SQL을 사용
- SQL은 데이터 정의어DDL, 데이터 조작어DML, 데이터 제어어DCL로 구성됨
- DDL : 테이블 구조 정의에 사용. CRAETE, ALTER, DROP 문 등이 예시
- DML : 데이터 검색/삽입/삭제/수정에 사용. SELECT, INSERT, DELETE, UPDATE 문 등
- DDL : 데이터 사용 권한을 관리하는 데 사용. GRANT, REVOKE 문 등
# 데이터베이스 사용자
- 말 그대로 DB를 사용하는 사람이 누구냐에 관한 내용
- 사용자 : 일반 유저, 응용 프로그래머, SQL 유저, DB 관리자 (DBA)
- DBA : DB시스템을 총괄하는 사람
ㄴ 보통 DB마다 최소 관리자 한 명을 배치함
ㄴ DBA는 데이터 설계, 구현, 유지보수 전 과정을 담당하며, DB 사용자
ㄴ DB 사용자 통제, 보안, 성능 모니터링, 전체 데이터 관리 및 이동, 복사 등의 제반 업무 담당

# DBMS
- 사용자와 DB를 연결해 주는 소프트웨어
- 데이터베이스의 생성, 공유, 관리 기능을 제공하는 총체적 역할

# DBMS 구성
- DML/DDL 컴파일러 : SQL을 번역함
- 임베디드 DML 컴파일러 : 응용프로그램에 삽입된(embedded) SQL을 번역함
- 질의 처리기 : 번역된 SQL을 처리하는 알고리즘
- 그 외 트랜잭션 관리자, 파일 관리자, 버퍼 관리자 등의 기능들이 들어가있음
# DBMS는 왜 쓸까?
- 그냥 데이터를 파일로 저장해두면 될 것을 왜 굳이 DBMS를 쓰는걸까
- 일단 DBMS는 데이터의 구조를 관리하고, 데이터 값은 데이터베이스에 저장함
- 이렇게 분리된 구조는 다음과 같은 장점들을 가짐
ㄴ 데이터 중복 최소화 : DBMS를 거쳐서 데이터를 공유하므로 중복 가능성 ↓
ㄴ 데이터 일관성 유지 : 중복 제거로 데이터 일관성
ㄴ 데이터 독립성 유지 : 데이터 정의와 프로그램 간 독립성 유지 가능
ㄴ 데이터 무결성 유지
ㄴ 데이터 표준 준수 용이 등등
ㄴ 관리 기능 제공 : 데이터 복구, 보안, 동시성 제어, 데이터 관리 기능 등을 제공
ㄴ 프로그램 개발 생산성 향상

# 데이터 모델
- 데이터가 어떻게 구조화되어 저장되는지를 결정하는 이론적 방법론
- 현재 가장 많이 쓰이는 데이터 모델은 관계 데이터 모델relational data model
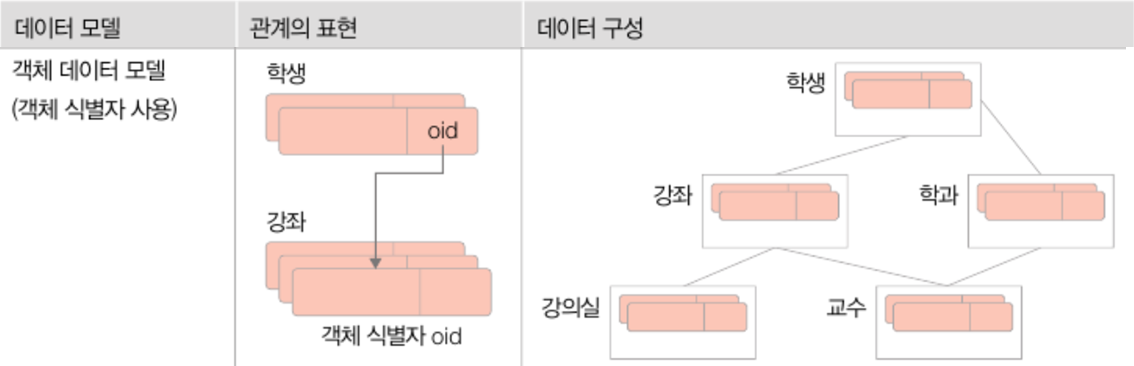
- 그 외 데이터 모델 종류 : 계층 데이터 모델, 네트웨크 데이터 모델, 객체 데이터 모델, 객체-관계 데이터 모델 등등
- 데이터 모델 구분의 가장 큰 기준은 데이터 간 관계를 표현하는 방법
※ 모델별 관계 표현 예시 (학생-강좌 관계표시)
1. 계층 데이터 모델
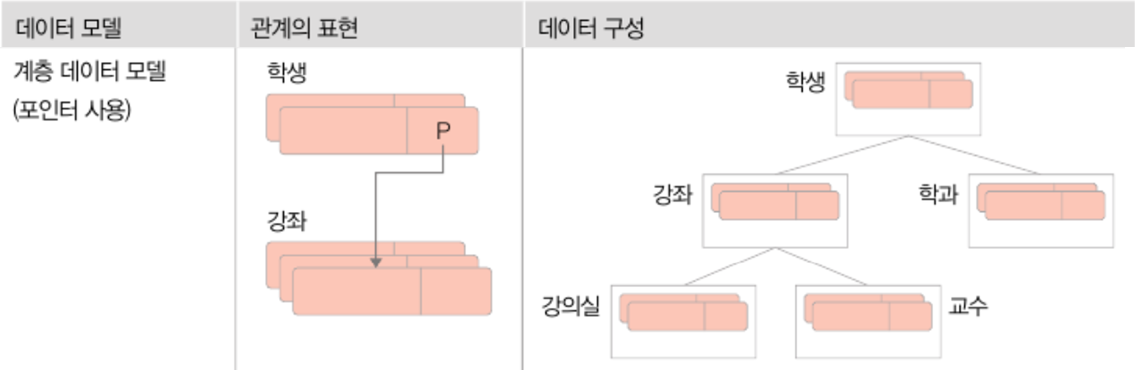
2. 네트워크 데이터 모델
3. 관계 데이터 모델

4. 객체 데이터 모델
# DB의 개념적 구조
- 데이터베이스 자체는 그냥 데이터를 모아놓은 것에 불과함
- 근데 내부적으론 데이터를 어떻게 분류할지, 어떻게 연결시킬지, 어떻게 통합할지 등등 많은 고민이 들어가게됨
- 때문에 점점 내부 구조가 복잡해지는데, 이를 개념적으로 이해하기 위한 안을 만듦
- 그게 바로 3단계 데이터베이스 구조3-layer db architecture
- 핵심은 데이터베이스를 보는 관점view에 따라 3단계로 분리했다는 것임
# 3단계 데이터베이스 구조
- DB 구조는 외부 단계, 개념 단계, 내부 단계로 나뉨
- 외부 단계 : 일반 사용자나 응용 프로그래머가 접근하는 계층
ㄴ 여러 개의 구조(스키마)가 존재할 수 있으며, 외부 스키마는 서브 스키마라고도 불림
ㄴ 일종의 뷰(view)에 해당하며, 웹에 빗대자면 프론트엔드 같은 느낌임
ㄴ ex) 학생 정보, 수강 정보, ... 등등이 외부 스키마임
- 개념 단계 : 전체 데이터베이스의 정의를 뜻함
ㄴ DBA가 관리하며, 통합 조직별로 하나만 존재
ㄴ 즉, 하나의 데이터베이스엔 하나의 개념 스키마conceptual schema가 존재
ㄴ 개념 스키마 안엔 데이터간 관계, 제약사항, 무결성 등의 내용이 포함됨
ㄴ ex) 학생 정보, 수강 정보 등의 외부 스키마는 '대학' 이란 전체 데이터베이스와 연결됨
- 내부 단계 : 데이터베이스가 물리적 저장 장치에 저장되는 실질적 방법을 표현한 것
ㄴ 내부 스키마는 하나만 존재
ㄴ 내부 스키마엔 인덱스, 데이터 레코드 배치법, 데이터 압축 등의 내용이 포함됨
ㄴ ex) '대학' 이란 데이터베이스가 실제 하드 디스크에 저장되는 방법/구조
※ 오해할까봐 적지만 각 단계는 그에 걸맞는 각각의 스키마를 가지는 것뿐임. 단계와 스키마는 동의어가 아님

# 데이터베이스 단계 간 매핑
- 3단계 데이터베이스 구조에서 각 단계는 매핑을 통해 서로 연결되고 대응됨
ㄴ 외부/개념 매핑 : 외부 스키마의 데이터가 개념 스키마의 어느 부분에 해당되는지 대응시킨 것
ㄴ 개념/내부 매핑 : 개념 스키마의 데이터가 내부 스키마의 물리적 장치 중 어디에 어떻게 저장되는지 대응시킨 것
※ 매핑과 스키마 예시 (대학의 수강신청 + ER다이어그램)
[1] 데이터베이스 구축(개념 스키마 설계)
- 대학의 수강신청과 관련된 DB를 구축하려면?
- 학생, 등록, 강의실, 교수 등등에 관한 테이블 필요
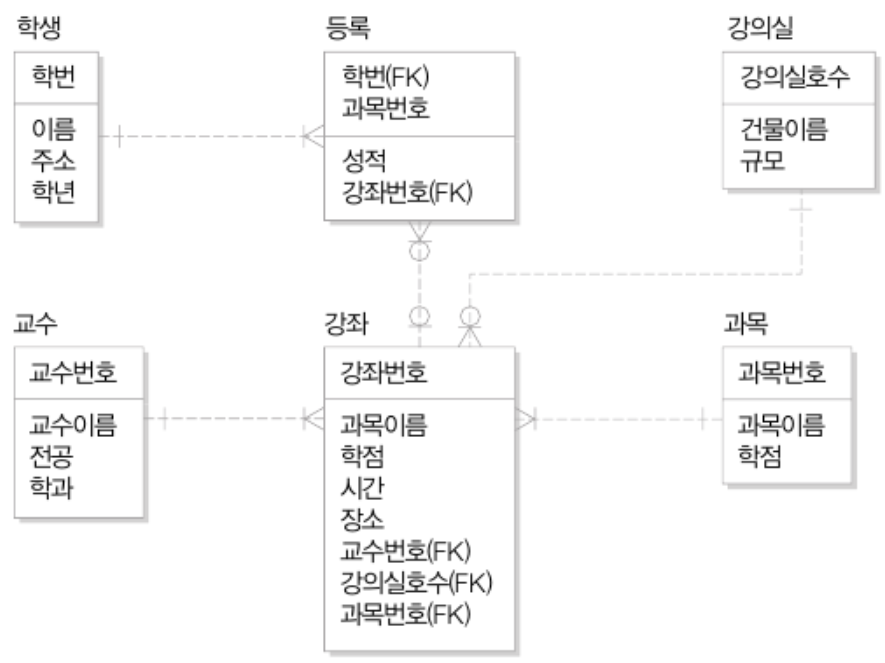
[2] 수강등록 관련 구성(외부 스키마 설계)
- 시간표 작성 업무는 수업관리과에서 처리함
- 수강등록 업무는 학사관리과에서 처리함
- 그렇다면 이들 각각이 수행하는 업무를 표현하기 위해 필요한 것들은?
- 전체 DB(개념 스키마)에서 일부만 떼다가 쥐어주면 됨
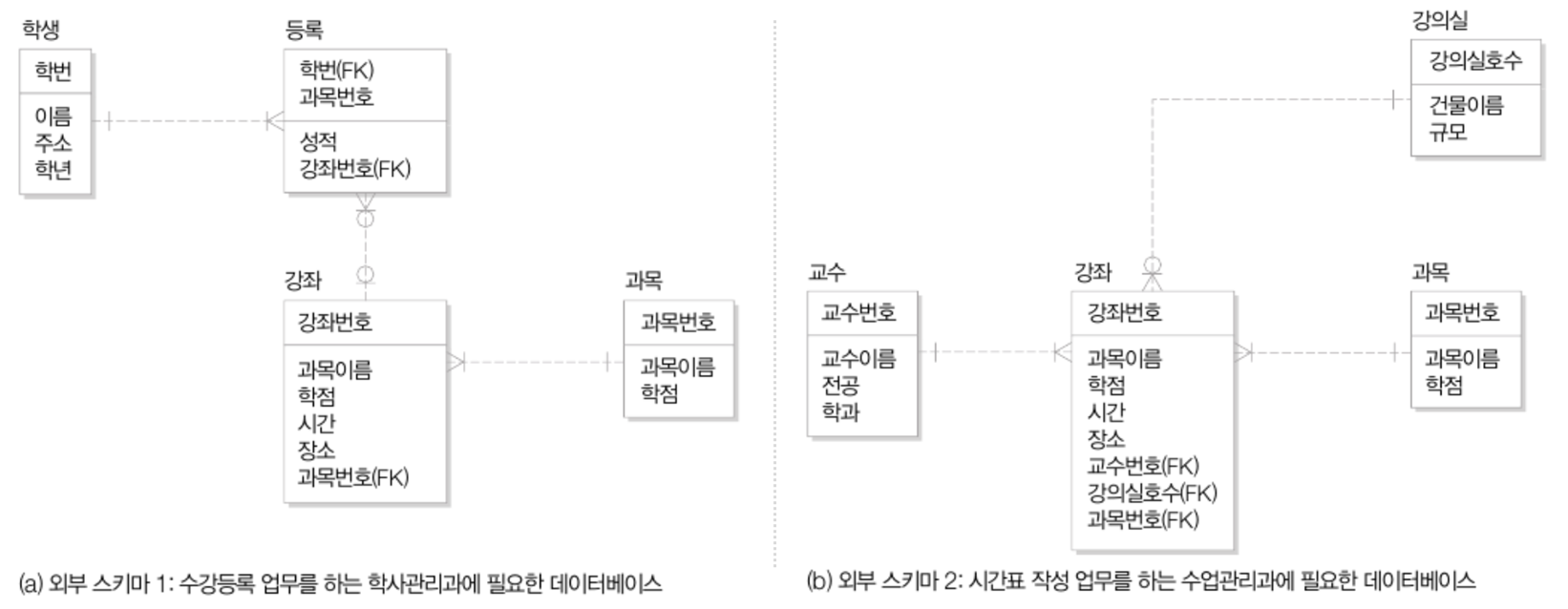
[3] 개념 스키마 저장방법 정의(내부 스키마)
- 말이 어려운데, 각 테이블과 데이터의 타입을 정의하란 말과 비슷함
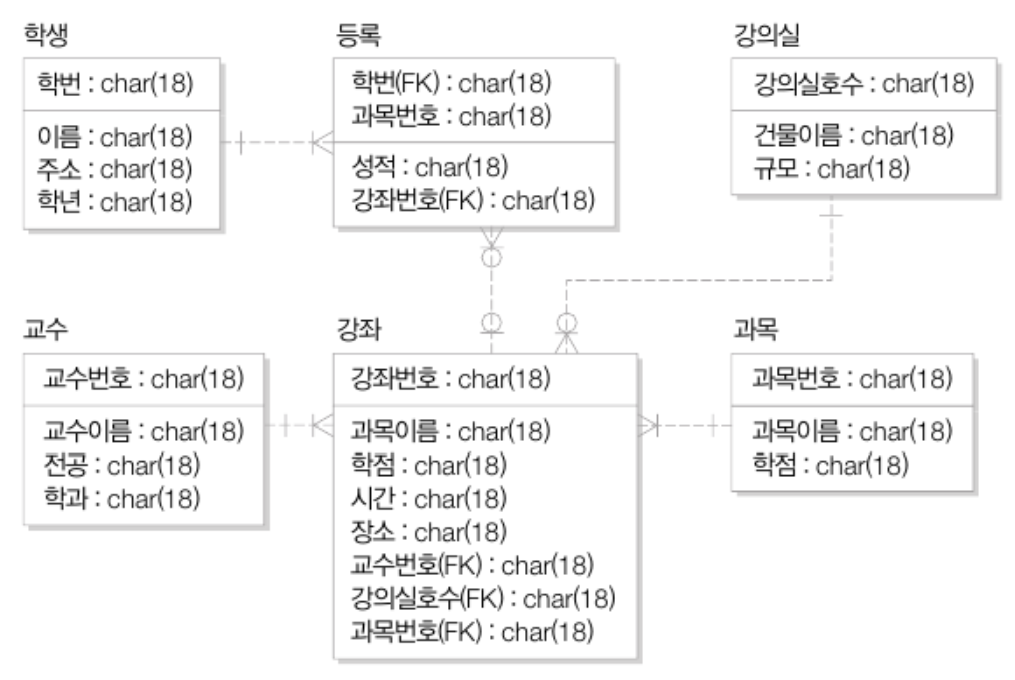
[4] 데이터베이스 3단계 구조 전체정리
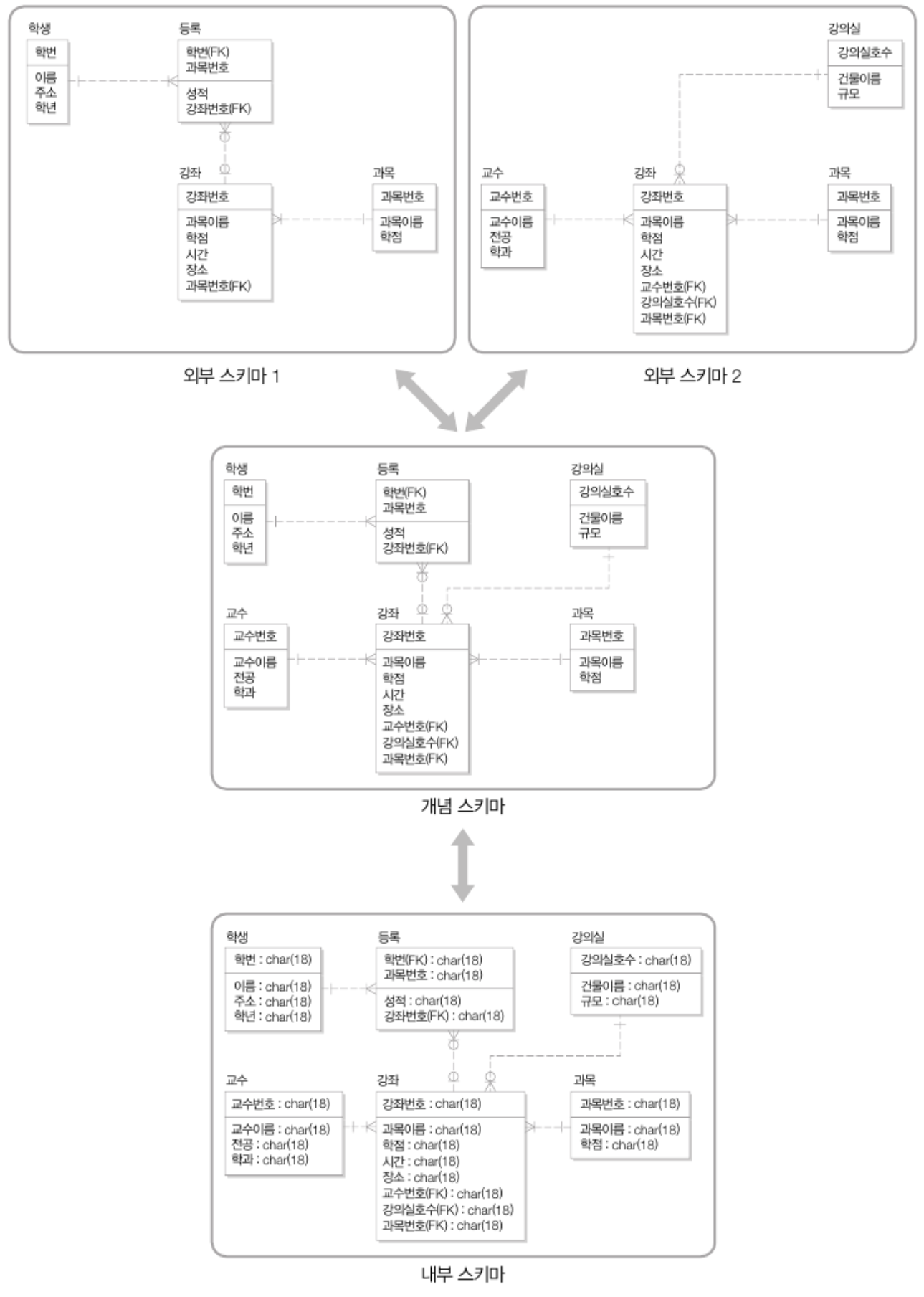
# 그래서 DB 3단계 구조 효과가 뭐임?
- 가장 큰 효과(특징)는 데이터 독립성data independence
- 즉, 각 단계 내의 변경이 다른 단계에 영향을 주지 않는다는 특징을 말함
ㄴ 외부 스키마는 개념 스키마가 변경되어도 영향받지 않음 (논리적 데이터 독립성)
ㄴ 내부 스키마가 변경되어도 개념 스키마는 영향받지 않음 (물리적 데이터 독립성)
2. 관계 데이터 모델
# 관계 데이터 모델이란
- 데이터와 이들 사이의 관계를 테이블을 사용하여 표현한 데이터베이스 모델
- 1970년 수학자인 에드가 코드가 제시함
- 애초에 수학자가 각잡고 집합론에 근거해서 만든거라 매우 짜임새있고 탄탄함

# 릴레이션
- 릴레이션 자체는 행과 열로 구성된 테이블을 뜻함
- 흔히들 테이블이라고 말하는데 둘은 정확히 동일한 의미임
- 수학의 집합론에서 나온 개념으로, 데이터를 각 집합으로 분류한 후 각 집합의 원소들을 엮어 행과 열로 표현함

# 관계(relationship)
- 관계에는 릴레이션(테이블) 내의 관계, 릴레이션(테이블) 간의 관계가 존재
- 릴레이션 내의 관계 : 릴레이션 내 데이터들의 집합으로 표현
- 릴레이션 간의 관계 : 각 릴레이션을 대표하는(식별하는) 값을 이용해 표현

# 릴레이션 스키마 & 인스턴스
- 스키마 : 릴레이션에 어떤 정보가 담길지 정의해둔 것
ㄴ 테이블의 헤더에 나타나며 각 데이터의 특징(속성), 자료 타입 등의 정보를 담고있음
ㄴ 속성 : 릴레이션 스키마의 각 열
ㄴ 차수 : 속성의 개수
ㄴ 도메인 : 속성이 가질 수 있는 값들의 집합

- 인스턴스 : 테이블에 실제로 저장된 데이터의 집합
ㄴ 튜플 : 릴레이션의 각 행
ㄴ 카디날리티 : 튜플의 개수

# 릴레이션 규칙
- 릴레이션은 특정한 규칙을 준수해야 하는데 해당 내용은 다음과 같음
① 속성은 단일 값만
② 속성은 중복 X
③ 속성의 값은 도메인 내에서만
④ 속성의 순서는 상관X
⑤ 튜플의 순서도 상관X
⑥ 중복된 튜플은 불가

# 키
- 릴레이션에서 특정 튜플을 식별할 때 사용하는 속성(혹은 속성의 집합)
- 자동차 키랑 똑같은 역할 (내 차 찾는데 쓰는거니까)
- 키는 릴레이션 간의 관계를 맺는 데도 사용됨


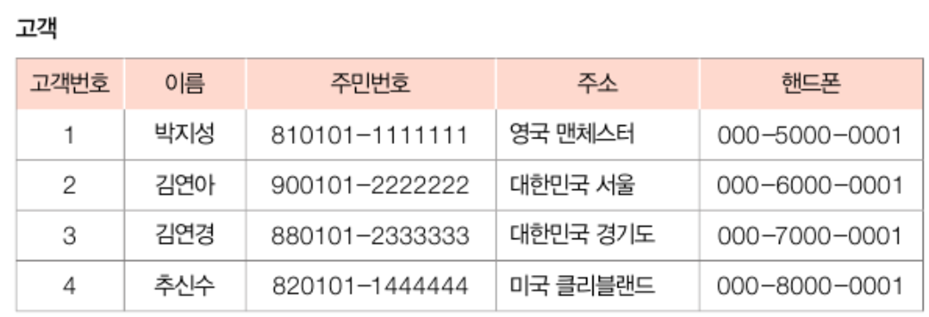
## 슈퍼키
이때 후보키가 두 개
- 튜플을 유일하게 식별할 수 있는 속성(혹은 속성의 집합)
- 경우에 따라 슈퍼키는 얼마든지 여러개가 나올 수 있음
ㄴ 아래 고객 릴레이션을 예로들면 (주민번호), (이름, 주민번호), (고객번호), (고객번호, 이름, 주소), ...
ㄴ 물론 슈퍼키를 구성하는 속성이 많아질수록 복잡해지므로 현실성은 떨어지지만
## 후보키
- 튜플을 유일하게 식별할 수 있는 속성의 최소 집합
- 이때 후보키가 두 개 이상의 속성으로 이루어진 경우 복합키 라고 함
- 위 고객 릴레이션에서 후보키는 고객번호, 주문번호가 후보키
- 아래 주문 릴레이션에선 (고객번호, 도서번호) 집합이 후보키가 됨

## 기본키
- 여러 후보키 중 대표로 선정한 키
- 후보키가 하나면 그게 곧 기본키, 여러개면 그중 하나 고르면 됨
- 단, 키의 대표인 만큼 몇 가지 고려사항이 존재하는데 이를 기본키 제약조건이라고 함
① NULL 값 X
② 키 값의 변동 허용X
③ 속성 개수는 최소화
④ 튜플을 식별할 수 있는 고유값이어야 함
⑤ 기타 문제의 소지가 없어야함(개인정보나 뭐 그런것들)
## 대리키
- 데이터 자체에 마땅한 기본키가 없을 경우 만드는 가상의 기본키
- 일련번호 같은게 대리키에 속함(인조키 라고도 함)
- 통상 DBMS에서 임의로 생성되는데 어차피 봐도 뭔뜻인지 알기 어려움
## 대체키
- 기본키가 되지 못한 후보키
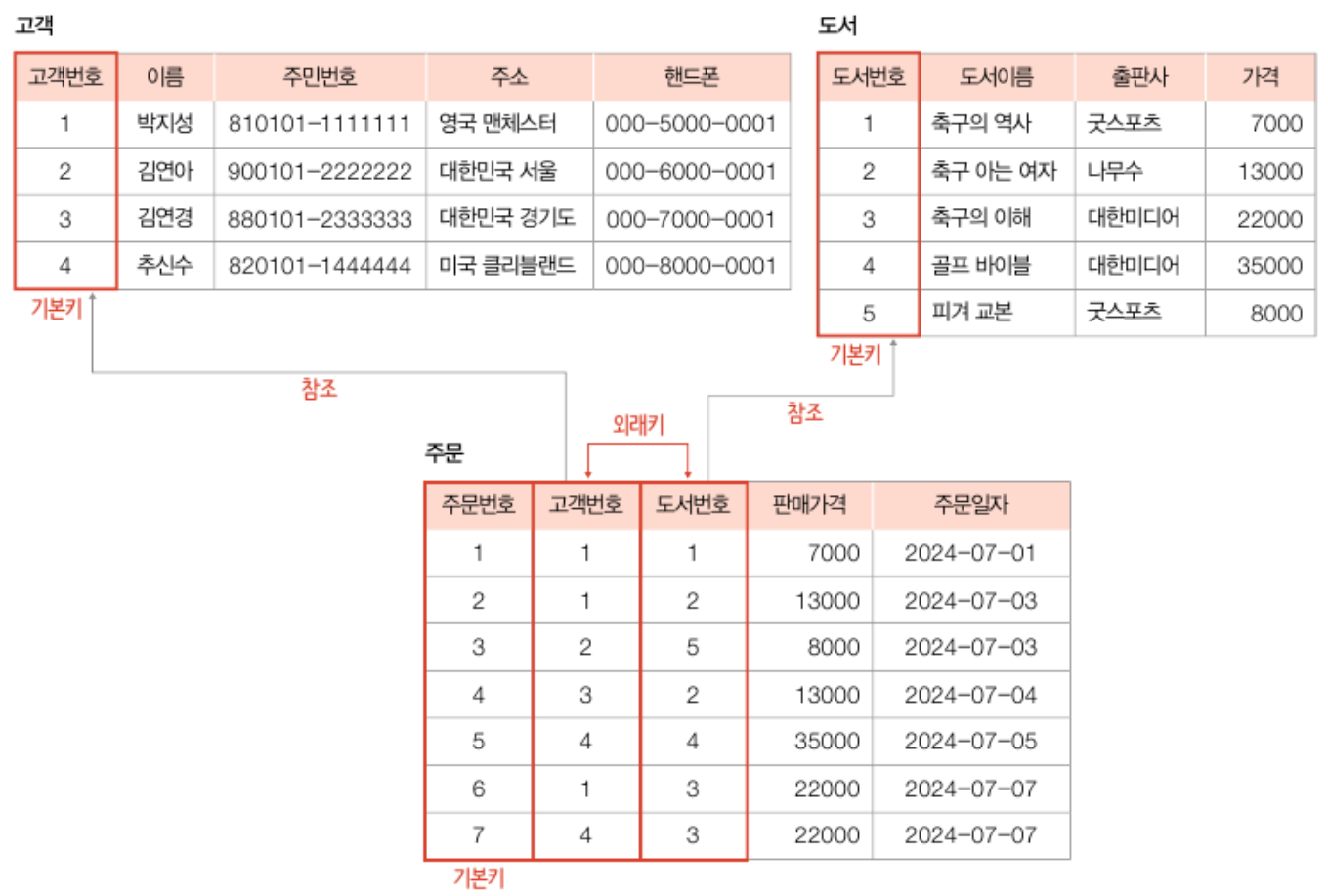
## 외래키
- 다른 릴레이션의 기본키를 참조하는 속성
- 릴레이션 간의 관계를 표현하기 위한 키임
- 외래키 제약조건
① NULL 값 O, 중복값 O
② 참조하고(외래키) 참조되는(기본키) 양쪽 릴레이션의 도메인이 서로 같아야함
③ 참조되는(기본키) 값이 변경되면 참조하는(외래키) 값도 변경돼야함
④ 자기 자신의 기본키를 참조하는 외래키도 가능
⑤ 외래키는 기본키의 일부가 될 수 있음

3. 무결성 제약조건
# 제약조건과 관계대수
- 관계 데이터 모델은 릴레이션을 정의할 때 제약조건과 관계대수도 함께 정의함
- 제약조건 : 저장될 데이터 값이 가져야 하는 제약
ㄴ ex) 나이는 음수가 되면 안됨, 주문은 고객번호를 참조해 생성돼야함, ...
- 관계대수 : 어떤 데이터를 어떻게 찾는지에 대한 처리 절차를 명시하는 언어
ㄴ 말이 어려운데, 그냥 질의 방법을 기술해놓은 언어를 뜻하는것 뿐임
# 제약조건이 왜필요함?
- DB에 저장된 데이터는 결함이 없어야되고 신뢰성이 생명임
- 예를 들어, 고객1이 주문한적도 없는 물건이 주문한걸로 돼있으면 안되지 않겠음?
- 따라서 데이터의 삽입, 삭제, 수정 등등 모든 행위에 여러 제약조건이 붙게됨
# 무결성 제약조건
- 데이터 무결성integrity : 데이터의 일관성과 정확성을 지키는 것
- 무결성 제약조건 종류 : 도메인 무결성 제약조건, 개체 무결성 제약조건, 참조 무결성 제약조건
# 도메인 무결성 제약조건
- 튜플은 각 속성의 도메인에 지정된 값만을 가져야 한다는 조건
- 속성값과 관련된 무결성으로, 자바로 따지면 자료형 선언과 비슷한 느낌
- SQL문에선 데이터 타입, 널 여부, default값, 체크 등으로 지정하게 됨
# 개체 무결성 제약조건
- 기본키는 NULL 값을 가져서는 안되며, 릴레이션 내에 오직 하나의 값만 존재해야 한다는 조건
- 그냥 앞서 언급한 기본키 제약조건을 준수해야 한다는 조건이랑 똑같은 말
- 기본키 제약이라고도 함
# 참조 무결성 제약조건
- 관계 대응이 안되는 외래 키값을 가질 수 없다는 조건. 쉽게 말해
- 자식 릴레이션의 외래키는 부모 릴레이션의 기본키와 도메인이 같아야 하고,
- 자식 릴레이션의 값이 변경될 때 부모 릴레이션의 제약을 받는다는 조건
- 외래키 제약이라고도 함

NOTE
Unique 제약조건(유일성, 고유성 제약조건) 이란것도 있는데, 속성의 모든 값은 서로 같은 값이 없어야 한다는 조건. 실제 DMBS에선 앞선 세 가지 무결성 제약조건에 유니크 제약조건도 함께 사용함
# 무결설 제약조건 이행하기
- 릴레이션은 데이터 변경이 발생할 때마다 제약조건 위배의 소지가 발생함
- 따라서 데이터의 변경(삽입, 수정, 삭제)이 발생할 때마다 제약조건 준수 여부를 체크해야함
# 개체 무결성 제약조건 이행예시
- 기본키와 관련된 내용이라 간단함

# 참조 무결성 제약조건 이행예시
- 릴레이션 간의 참조 관계와 관련된 내용이라 처리가 좀더 복잡함
- 삽입(자식 릴레이션에서)

- 삭제(부모 릴레이션에서)
ㄴ 자식 릴레이션에서 삭제야 부모 릴레이션에 아무 영향도 없으므로 바로 삭제가능
ㄴ 그러나 부모 릴레이션에서 삭제는 자식한테 영향을 미칠 수 있음

ㄴ 위 경우 네 가지 조치방법이 존재하는데, 원하는 옵션을 고르면됨

- 수정은 삭제+삽입 명령을 순차적으로 수행한다고 생각하면 됨
4. 관계대수
# 관계대수
- 릴레이션에서 원하는 결과를 얻기 위해 질의하는 방법을 기술한 언어
- DMBS 내부의 처리 언어로 사용됨
- 사실 관계 데이터 모델에선 관계대수랑 관계해석 둘 다 필요하긴 함
- 실제로 SQL 언어는 관계해석을 기반으로 함
- 그러나 DBMS 내부에선 관계대수에 기반한 연산을 수행하므로 여기에선 관계대수만 다루는걸로
# 사실 릴레이션은 수학(집합)임
- 릴레이션 자체가 사실 수학의 집합론을 그대로 차용함
- 예를 들어, A=[2,4], B=[1,2,3] 이란 집합이 있다고 생각해보자
ㄴ A X B = { (2,1), (2,2), (2,3), (4,1), (4,2), (4,3) }이 됨 (카티션 프로덕트)
ㄴ 그리고 릴레이션(R)이란 것 자체가 원래 수학적으로 카티션 프로덕트의 부분집합을 의미함
ㄴ 즉, A, B 카티션 프로덕트의 부분집합은 {(2,1)}, {(2,1), (2,2)}, ... 등이 되는데
ㄴ R1={ (2,1), (2,2) }, R2={ (4,1), (4,2), (4,3) }, ... 등이 모두 수학적 의미에서의 릴레이션인거
- 데이터베이스의 릴레이션은 위 정의를 그대로 차용해 행/열로 표현한 것뿐임
ㄴ 학번={2,4}, 과목={DB, 자료구조, 프로그래밍}이 있다고 치면
ㄴ 학번 X 과목 = { (2, DB), (2, 자료구조), (2, 프로그래밍), (4, DB), (4, 자료구조), (4, 프로그래밍) }이 되고
ㄴ 아래는 R1 = { (2, DB), (2, 자료구조), (4, 프로그래밍) } 릴레이션을 테이블로 그린것

# 관계대수 연산자
- 릴레이션 연산에 사용되는 기호를 뜻함 (+, -, *, / 처럼 간단하면 좋으련만)
- 관계대수 연산자는 기준에 따라 종류를 구분하는 법이 몇개됨
① 일반적 관계대수 연산자 종류 : 순수 관계연산relational operations, 일반 집합연산 set operations
ㄴ 순수 관계연산 : 셀렉션, 프로젝션, 조인, 디비젼, 리네임
ㄴ 일반 집합연산 : 합집합, 교집합, 차집합, 카티션 프로덕트
② 피연산자 개수에 따른 종류 : 단항 연산자, 이항 연산자
③ 연산자 타입에 따른 종류 : 기본 연산자, 기본 연산자에서 유도되는 유도 연산자

# 관계대수식
- 릴레이션 간 연산의 순서(절차)를 기술한 언어
- 기본적 형태 (R: 릴레이션)
ㄴ 단항 연산자 : 연산자<조건> 릴레이션
ㄴ 이항 연산자 : R1<조건> R2

# 집합연산 (합/교/차집합, 카티션 프로덕트)
- 두 개의 릴레이션을 대상으로 함(이항 연산자)
- 카티션을 제외하면 합병가능union compatible해야 성립됨
- 합병 가능이란
ㄴ 피 연산자들의 차수가 같아야 함(즉, 두 릴레이션의 속성 개수 동일)
ㄴ 피 연산자들의 속성 순서도 같아야 함
ㄴ 피 연산자들의 속성이 각각 동일한 도메인으로 대응돼야함
ㄴ 속성 이름이 동일할 필요는 없음
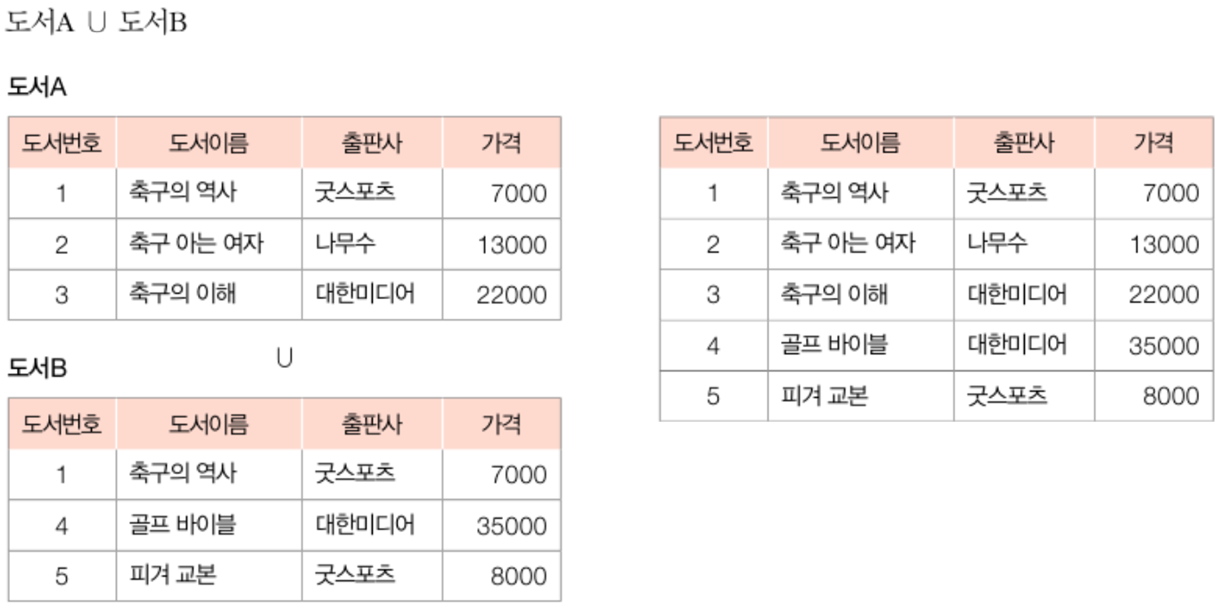
※ 집합연산 예시 살펴보기
## 합집합
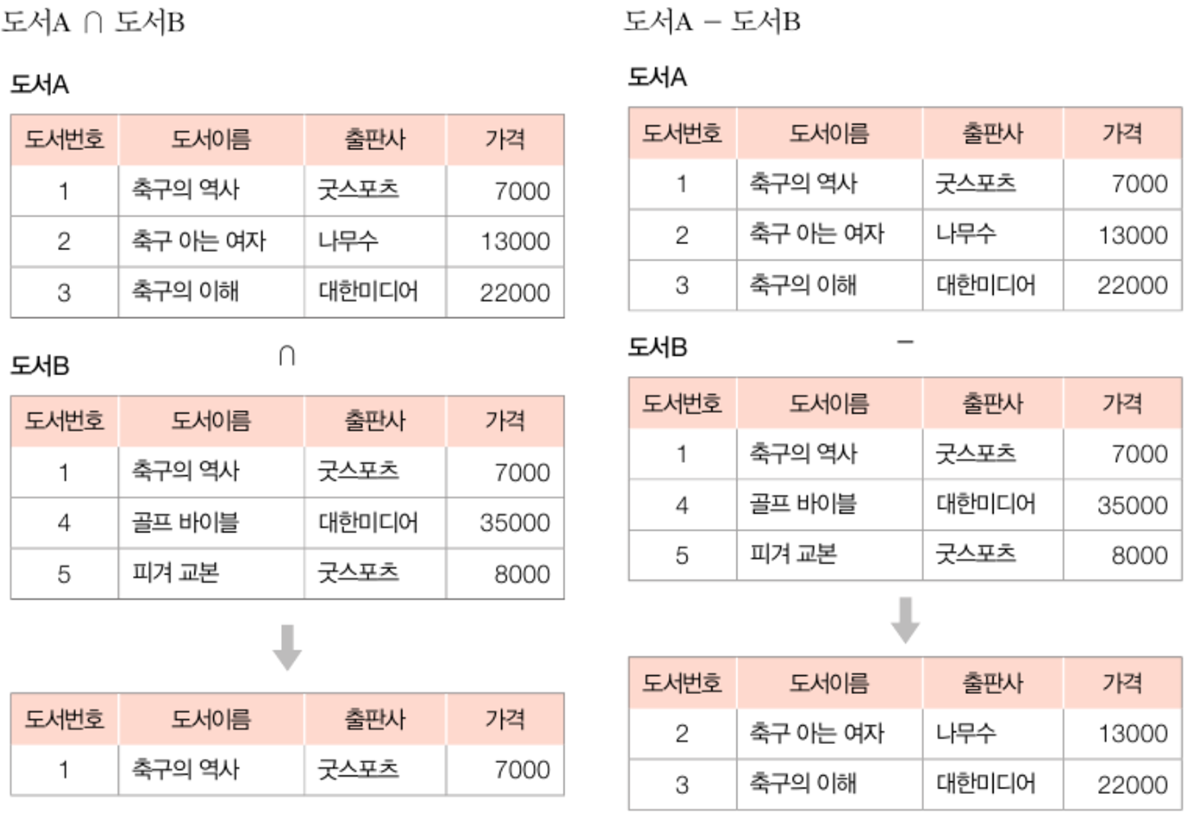
## 교집합, 차집합
## 카티션 프로덕트
- 결과 릴레이션의 차수가 증가함
- 만약 두 릴레이션에 동일한 속성 이름이 존재하면?
ㄴ <릴레이션>.<속성> 으로 표기하거나
ㄴ 그냥 순서만 잘 조정해서 표기함
# 셀렉션 (순수 관계연산)
- 릴레이션의 튜플을 추출하기 위한 연산
- 하나의 릴레이션을 대상으로 함(단항 연산자)
- 작성형식: σ<조건>(R)

# 프로젝션 (순수 관계연산)
- 릴레이션의 속성을 추출하기 위한 연산
- 하나의 릴레이션을 대상으로 함(단항 연산자)
- 작성형식: π<속성리스트>(R)

# 디비전 (순수 관계연산)
- 특정 값들을 모두 보유한 튜플을 반환하는 연산
- 릴레이션 자체보단 릴레이션 속성값의 집합으로 연산하는 특이 케이스임
- 사실 거의 안씀 (어차피 조인으로 다 할수있는거라)
- 작성형식: R ÷ S

# 조인 (순수 관계연산)
- 두 릴레이션의 공통 속성을 기준으로 속성값이 같은 튜플을 결합하는 연산
- 두 릴레이션을 대상으로 함(이항 연산자)
- 조인 연산은 카티션 프로덕트 연산 후 셀렉트 연산을 수행한 것과 동일
- 구분 : 기본 조인 연산, 확장된 조인 연산
ㄴ 기본 조인 연산 : 세타조인, 동등조인(이너조인), 자연조인
ㄴ 확장된 조인 연산 : 세미조인, 외부조인
- 작성형식: R ⋈c S (c: 조건)
## 세타조인, 동등(이너)조인
- 세타조인 : 두 릴레이션의 속성값을 비교해 조건을 만족하는 튜플을 반환함
- 동등조인 : 세타조인에서 걸어준 조건이 ' = ' 인 경우
- 작성형식: R ⋈(r조건s) S (r: R릴레이션 속성, s: S릴레이션 속성)

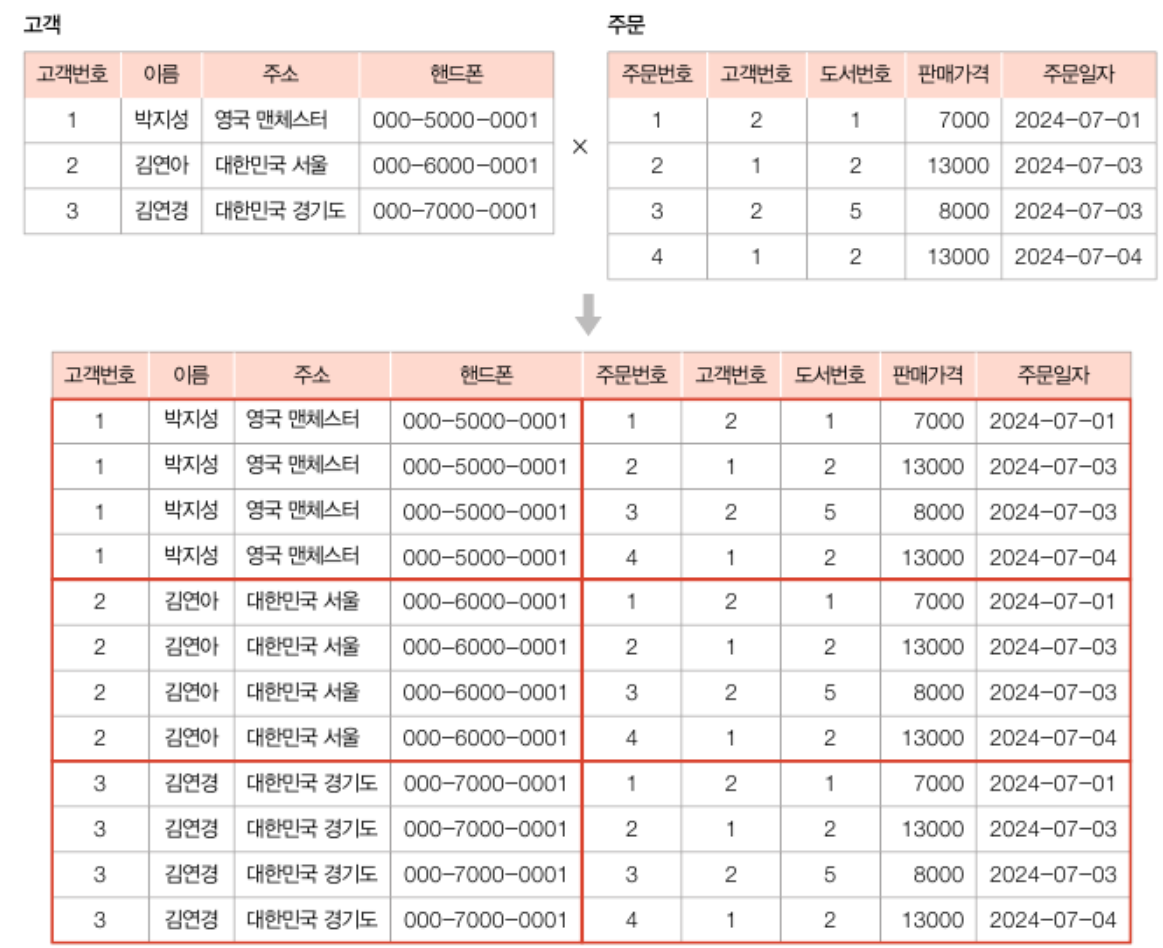
## 자연조인(natural join)
- 동등(이너)조인의 결과 릴레이션에서 중복된 속성을 제거한 것
- 작성형식: R ⋈N(r, s) S

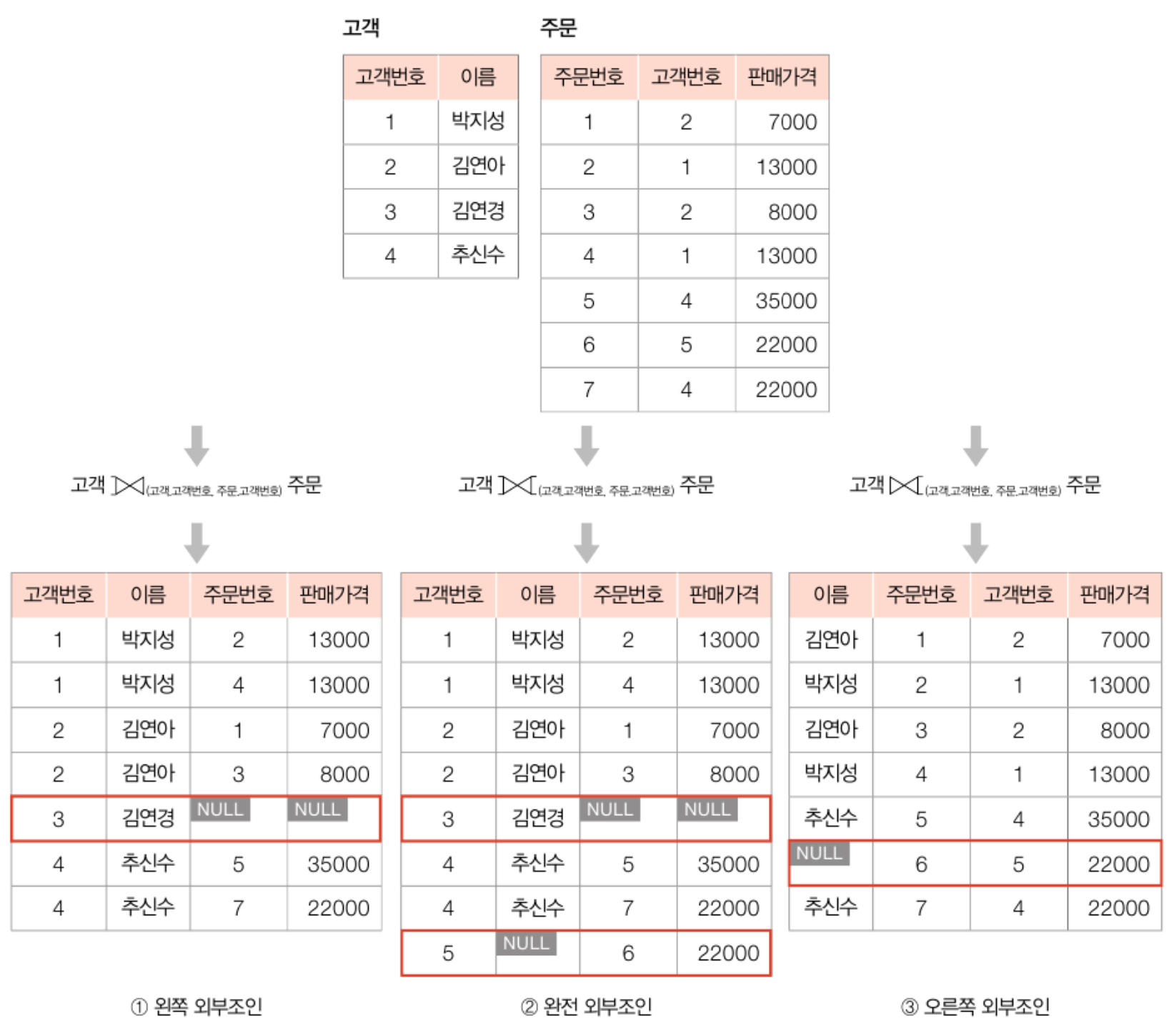
## 외부조인(outer join)
- 자연조인의 확장 형태로, 조인에 실패한 튜플도 모두 반환하는 조인
- 이때, 값이 없는 속성엔 NULL 값을 채워서 반환함
- 기준 릴레이션의 위치에 따라 left, right, full outer join으로 구분됨
- 작성형식: R ⟕ (r, s) S / R ⟖ (r, s) S / R ⟗ (r, s) S
## 세미조인
- 자연조인 후 한쪽 릴레이션의 결과만 반환하는 조인
- 작성형식: R ⋉ (r, s) S / R ⋊ (r, s) S
- 기호에서 닫힌 쪽 릴레이션의 튜플만 반환

# 질의 최적화(Query Optimization)
- DB에서 원하는 결과를 얻기 위해 관계대수식을 사용해 질의를 날림
- 근데 보통 동일한 결과라도 여러 대수식의 조합을 사용해 얻어낼 수 있음
- 이 경우, 이왕지사 효율적인 대수식을 선택하는게 당연히 좋음
- DBMS는 이 문제를 해결하기 위해 관계대수식의 결과에 부합하는 여러 대수식을 생성함
- 그리고 그중 가장 효율적인 대수식을 선택해 처리함
- 이러한 최적화 과정을 Query Optimization이라고 함
4. SQL 기초
# SQL
- IBM이 1970년대에 만든 관계형 데이터베이스 언어
- Java, C같은 완전한 프로그래밍 언어인건 X
- 데이터 부속어data sublanguage라고 지칭
- 이유는 데이터와 *메타 데이터의 생성/처리 문법만 갖고있기 때문
* 메타데이터 : 데이터 구조에 관한 데이터

5. 데이터 조작어
# 데이터 조작어 - 검색(SELECT)
- SELECT문은 질의어query라고 부름
- 아래는 SELECT문 문법의 기본형과 상세형

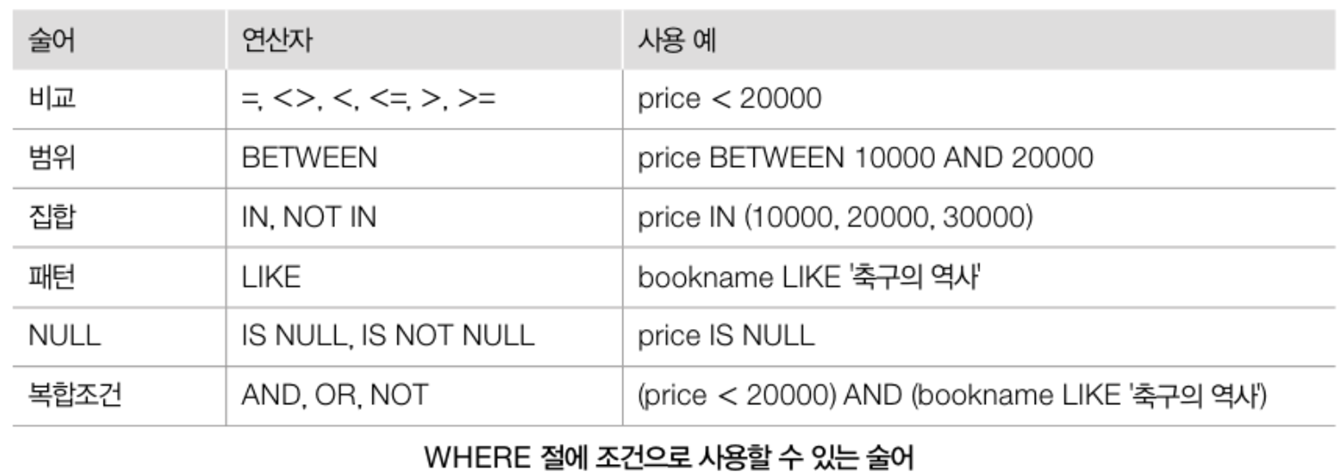
# WHERE 조건
- where 조건으로 사용할 수 있는 술어predicate는 비교,. 범위, 집합, 패턴, NULL로 구분됨
# 집계함수 aggregate function
- 말 그대로 집계(통계)를 내기 위한 함수
- DB에서 유의미한 정보를 뽑아내기 위해 주로 사용
ㄴ 올해 총 도서판매량, 도서판매액, 연령별 도서구매량 등등
ㄴ 여기서 '총 도서구매량'을 '연령별'로 구분지어 주는 기능이 GROUP BY임
* 집계 : SQL에선 '통계'란 말대신 '집계'라는 말을 사용(의미는 똑같음)

# GROUP BY & HAVING
- GUOUP BY : 속성값이 같은 것들끼리 묶는 기능
ㄴ 단독으로는 못쓰고 집계함수랑 반드시 함께 사용해야함
- HAVING : GROUP BY용 조건절
ㄴ GROUP BY된 결과에 적용되는 조건문임
ㄴ 반드시 WHERE 절보다 뒤에 나와야함

# 조인
- 한 테이블이ㅡ 행을 다른 테이블의 행에 연결해 결합하는 연산
- 대부분 조인이라 하면 동등(이너)조인을 뜻함
- 가끔 외부(outer)조인도 사용하는데, LEFT | RIGHT중 골라서 사용 (FULL OUTER JOIN은 MySQL에선 지원X)

# 부속질의 (sub query)
- 하나의 SQL 문 안에 다른 SQL 문이 중첩된 질의

# 집합연산
- SQL 문의 결과는 테이블(즉, 튜플의 집합)이고, 테이블 간의 연산을 수행하는 것을 집합연산이라고 함
- 종류 : 합집합(UNION), 차집합(MINUS), 교집합(INTERSECT), 카티션프로덕트(이건 그냥 From Book, Orders 처럼 나열만 하면 됨)
- MySQL에선 MINUS, INTERSECT 연산자를 지원하지 않음
ㄴ 각각 NOT IN, IN 연산자로 대체해서 구할 수 있기 때문
- 아래는 UNION, UNION ALL의 예시 (중복포함 여부로 갈림)

6. 데이터 정의어 - CREATE
# 데이터 정의어
- 테이블의 구조를 만드는 명령어
- 종류 : 테이블 구조 정의(CREATE문), 구조 변경(ALTER문), 구조 삭제(DROP문)
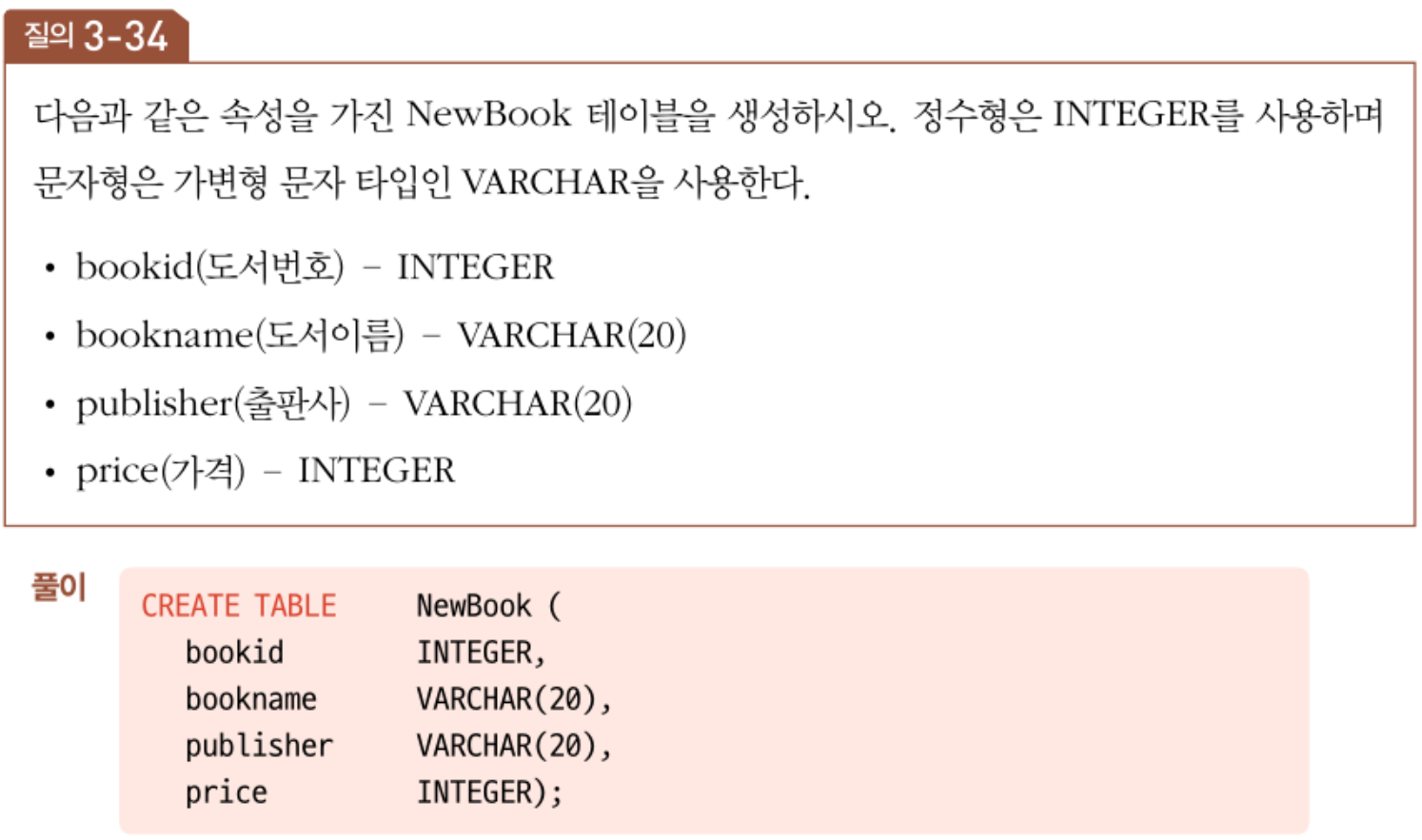
# CREATE 문
- 테이블 구성, 속성과 그에 관한 제약, 기본키/외래키를 정의하는 명령
- 아래는 CREATE 문의 문법
CREATE TABLE 테이블이름 (
{ 속성이름 데이터타입 [NULL | NOT NULL | NUIQUE | DEFAULT 기본값 | CHECK 체크조건] }
[PRIMARY KEY 속성이름(들)]
[FOREIGN KEY 속성이름 REFERENCES 테이블이름(속성이름)]
[ON DELETE {CASCADE | SET NULL|]
)
# 데이터타입
- 데이터 타입의 종류 및 상세 내용은 MySQL의 Reference Manual 참조
- 아래는 MySQL에서 사용하는 대표적인 데이터타입 종류임

※ CREATE 문 실습
- 외래키 제약조건 명시 주의사항 : 참조되는 테이블이 필요하며, 해당 참조 테이블의 기본키여야함
# 제약사항 추가해보기



7. 데이터 정의어 - ALTER, DROP
# ALTER 문
- 생성된 테이블의 속성, 제약을 변경
- 기본키 및 외래키 변경 등등
- ALTER 문 문법은 아래와 같음
ALTER TABLE 테이블이름
[ADD 속성이름 데이터타입]
[DROP COLUMN 속성이름]
[MODIFY 속성이름 데이터타입]
[MODIFY 속성이름 [NULL | NOT NULL]]
[ADD PRIMARY KEY(속성이름)]
[[ADD | DROP] 제약이름]
# ALTER문 예제
- Q1. NewBook테이블에 VARCHAR(13)의 자료형을 가진 isbn 속성을 추가하시오
ALTER TABLE NewBook ADD isbn VARCHAR(13); - Q2. NewBook 테이블에서 isbn 속성의 데이터 타입을 INTEGER형으로 변경하시오
ALTER TABLE NewBook MODIFY isbn INTEGER; - Q3. NewBook 테이블의 isbn 속성을 삭제하시오
ALTER TABLE NewBook DROP isbn; - Q4. NewBook 테이블의 bookname 속성에 NOT NULL 제약조건을 적용하시오
ALTER TABLE NewBook MODIFY bookname VARCHAR(20) NOT NULL; - Q5. NewBook 테이블의 bookid 속성을 기본키로 변경하시오
ALTER TABLE NewBook ADD PRIMARY KEY(bookid);
# DROP 문
- 테이블 삭제 명령
- 데이터'만' 삭제할땐 DELETE문을 사용함
- 주의사항 : A테이블이 B테이블의 기본키를 참조하고 있으면 B테이블을 바로 삭제할 수 없음
# DROP 문 예제
- NewBook 테이블을 삭제하시오
DROP TABLE NewBook; - NewCustomer 테이블을 삭제하시오. 아마 삭제가 거절될텐데 이유를 설명해보시오
-- Error Code 3730: -- Cannot drop table 'newcustomer' referenced by a foreign key constraint -- 'neworders_ibfk_1' on table 'neworders'. DROP TABLE NewCustomer; -- 정상 흐름 DROP TABLE NewOrders; DROP TABLE NewCustomer;
8. 데이터 조작어
# INSERT 문
- 테이블에 새 튜플을 삽입하는 명령
- 기본적인 문법은 아래와 같음
INSERT INTO 테이블이름[(속성리스트)] VALUES (값 리스트);
# INSERT 문 예제
- Q1. Book 테이블에 새로운 도서 '스포츠 의학'을 삽입하시오. 한솔의학서적에서 출간했으며, 가격은 90,000원임
-- 방법1 INSERT INTO Book(bookid, bookname, publisher, price) VALUES (11, '스포츠 의학', '한솔의학서적', 90000); -- 방법2 INSERT INT Book VALUES (12, '스포츠 의학', '한솔의학서적', 90000); - Q.2 Book 테이블에 동일한 도서를 넣는데 가격은 미정인 상태
-- 아래를 실행하면 price값에 NULL이 들어감 INSERT INTO Book(bookid, bookname, publisher) VALUES (14, '스포츠 의학', '한솔의학서적');
# Bulk Insert (대량 삽입)
- 한꺼번에 여러 개의 튜플을 삽입하는 방법을 말함
- SELECT 문을 병용해 INSERT 를 수행함
- EX) 수입도서 목록(Imported_book)을 Book 테이블에 모두 삽입하시오
INSERT INTO Book(bookid, bookname, price, publisher) SELECT bookid, bookname, price, publisher FROM Imported_book;
# UPDATE 문
- 특정 속성값을 수정하는 명령
- 다른 테이블의 속성 값도 사용할 수 있음
- 기본 문법은 아래와 같음
UPDATE 테이블이름 SET 속성이름1=값1 [, 속성이름2=값2, ...] [WHERE <검색조건>];
NOTE
MySQL Safe Updates 옵션
- UPDATE, DELETE 수행 시 실수 방지를 위해 걸어놓은 장치
- 해당 명령 사용시 기본키 속성만 사용하도록 강제하는 옵션이다
- MySQL Workbench 기준, [Edit] - [Preferences] - [SQL Editor] - 'Safe Updates' 체크 해제 가능
# UPDATE 문 예제
- Q1. Customer 테이블에서 고객번호가 5인 고객의 주소를 '대한민국 부산' 으로 변경하시오
UPDATE Customer SET address='대한민국 부산' WHERE custid=5; - Q2. Book 테이블에서 14번 '스포츠 의학'의 출판사를 imported_book 테이블의 21번 책 출판사와 동일하게 변경하시오
UPDATE Book SET publisher = (SELECT publisher FROM imported_book WHERE bookid=21) WHERE bookid=14;
# DELETE 문
- 테이블의 기존 튜플을 삭제하는 명령
- 튜플 삭제일뿐 테이블 삭제가 아님
- 기본 문법은 아래와 같음
DELETE FROM 테이블이름 [WHERE <검색조건>];
# DELETE 문 예제
- Book 테이블에서 도서번호가 11인 도서를 삭제하시오
DELETE FROM Book WHERE bookid=11; - 모든 고객을 삭제하시오 (테이블은 남겨둘 것)
DELETE FROM Customer; -- 사실 위 명령은 실행되지 못함 -- 이유는 Orders 테이블에서 -- Customer 테이블의 custid 속성을 외래키로 잠조중이기 때문
8. 내장함수
# 내장 함수란 (built-in function)
- DBMS가 제공하는 함수
- 상수나 속성 이름을 입력받아 단일 값을 반환함
- SELECT, WHERE, UPDATE 등 온갖 절에서 사용가능
- 종류들 궁금하면 https://dev.mysql.com/doc/refman/8.0/en/functions.html 참고
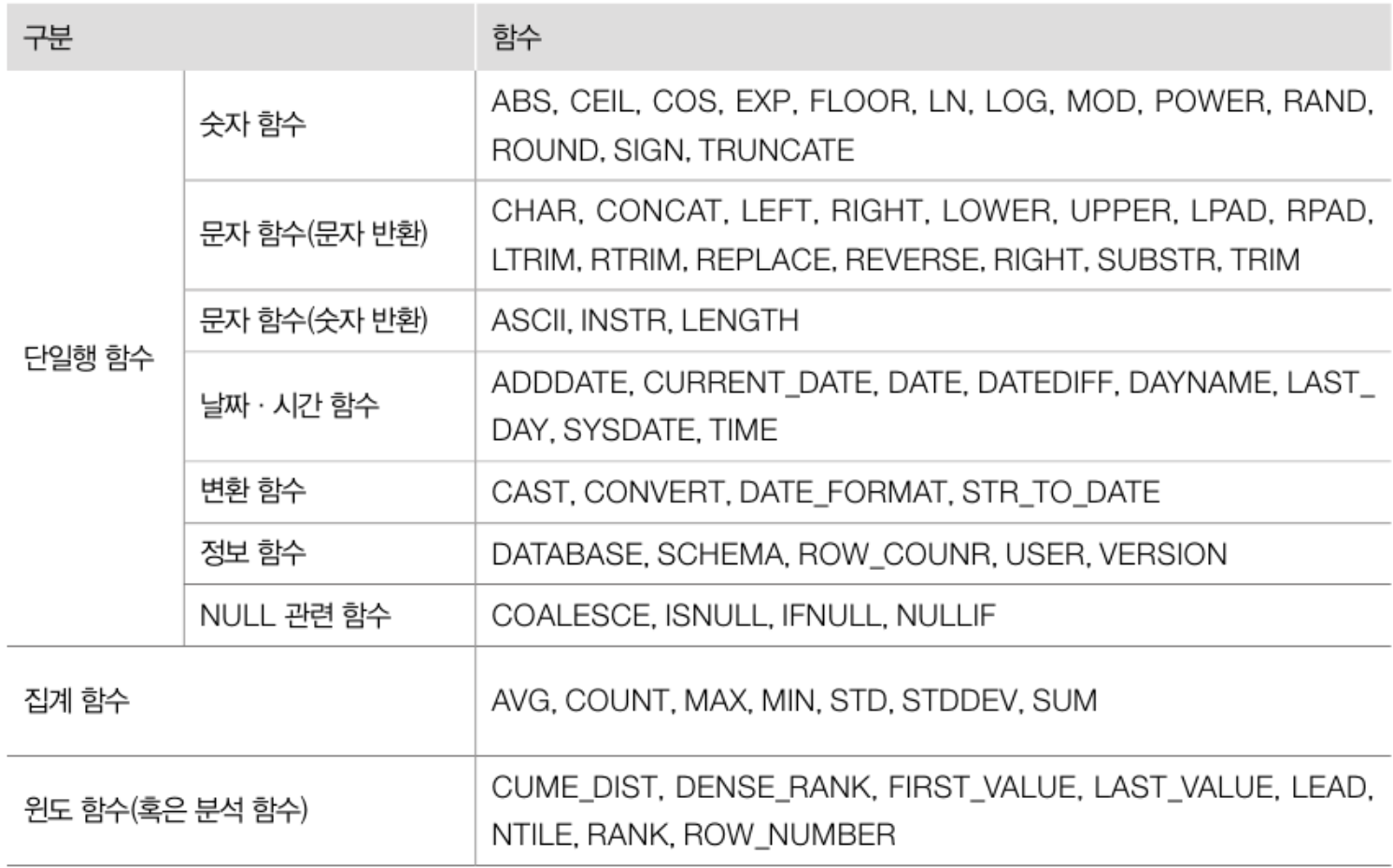
# 숫자 함수
- 사용 빈도가 높은 것들만 추려서 구경해보자
- Q1. 절댓값 구하기
SELECT ABS(+78), ABS(-78); - Q2. 4.875를 소수 첫째 자리까지 반올림 하기
SELECT ROUND(4.875, 1); SELECT ROUND(4.875, 0); -- 5 SELECT ROUND(4.875, -1); -- 0 - Q3. 고객별 평균 주문 금액을 100원 단위로 반올림한 값을 구하시오
SELECT custid '고객번호', ROUND(SUM(saleprice)/COUNT(*), -2) '평균금액' FROM Orders GROUP BY custid;
NOTE
MySQL에선 FROM 절이 없어도 SELECT 문이 사용 가능한 반면, Oracle에선 FROM절이 필수이다. 이는 DBMS 마다 설정이 다르기 때문이며, Oracle은 일시적인 연산 작업을 처리할땐 가상의 dual이란 테이블을 사용
# 문자 함수
- 주로 CHAR나 VARCHAR 데이터 타입을 처리함
- Q1. 도서 제목에 야구가 포함된 도서를 농구로 변경하시오
SELECT bookid '도서번호', REPLACE(bookname, '야구', '농구') '도서제목' FROM Book; - Q2. 굿스포츠에서 출판한 도서의 제목과 제목의 문자 수, 바이트 수를 나타내시오
(참고: CHAR_LENGTH 함수는 문자 수 셀때 공백도 하나의 문자로 간주됨)
SELECT bookname '도서제목', CHAR_LENGTH(bookname) '문잦 수', LENGTH(bookname) '바이트 수' FROM Book; - Q3. 마당서점 고객 중 성이 같은 사람이 몇 명이나 되는지 성별로 구하시오
SELECT SUBSTR(name, 1, 1) '성', COUNT(*) '인원' FROM Customer GROUP BY SUBSTR(name, 1, 1);
# 날짜/시간 함수
- DB에 날짜는 단순 문자열보단 날짜형 데이터로 저장하는 것을 권장함
- 날짜형 데이터 처리 시 INTERVAL이란 키워드를 쓰면 n일 전/후 설정도 가능
- Q1. 주문일로부터 10일 후 매출을 확정한다고 할 때, 각 주문의 확정일자를 구하시오
SELECT orderid '주문번호', orderdate'주문일', ADDDATE(orderdate, INTERVAL 10 DAY) '확정일자' FROM Orders; /* 1 2024-07-01 2024-07-11 2 2024-07-03 2024-07-13 3 2024-07-03 2024-07-13 4 2024-07-04 2024-07-14 ... */ - Q2. 7월 7일에 주문받은 도서의 정보들을 나타내시오 (단, 주문일 표기는 %Y-%m-%d)
SELECT orderid '주문번호', DATE_FORMAT(orderdate, '%Y-%m-%d') '주문일', custid '고객번호', bookid '도서번호' FROM Orders WHERE orderdate=STR_TO_DATE('20240707', '%Y%m%d'); /* 6 2024-07-07 1 2 7 2024-07-07 4 8 */ - Q3. DBMS 서버에 설정된 현재 날짜와 시간, 요일을 출력하시오
SELECT DATE_FORMAT(SYSDATE(), '%Y-%m-%d %h:%i %a'); -- 2024-11-16 09:07 Sat
※ 함수 모음집
# 문자 관련 내장 함수
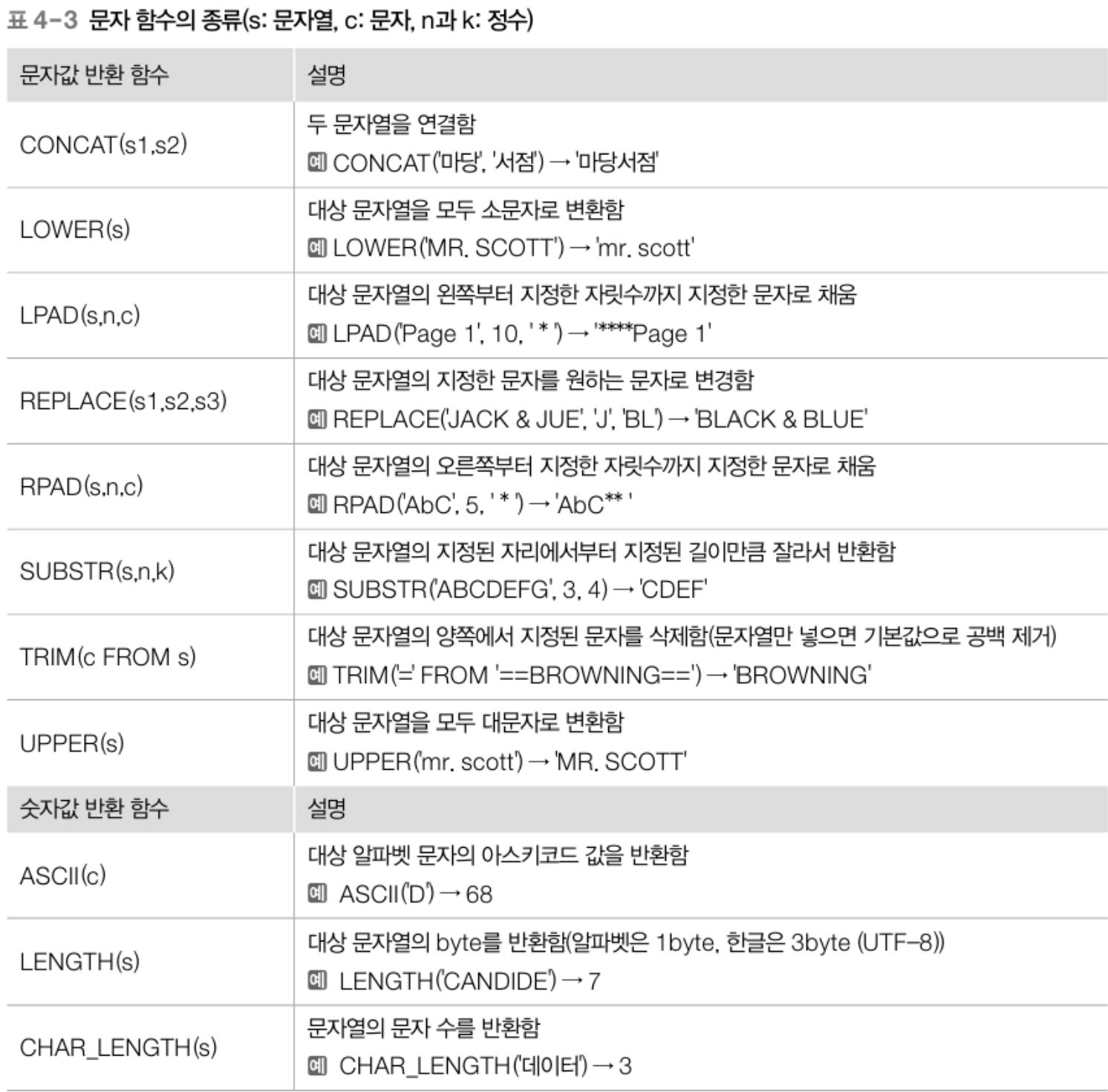
# 시간 관련 내장 함수
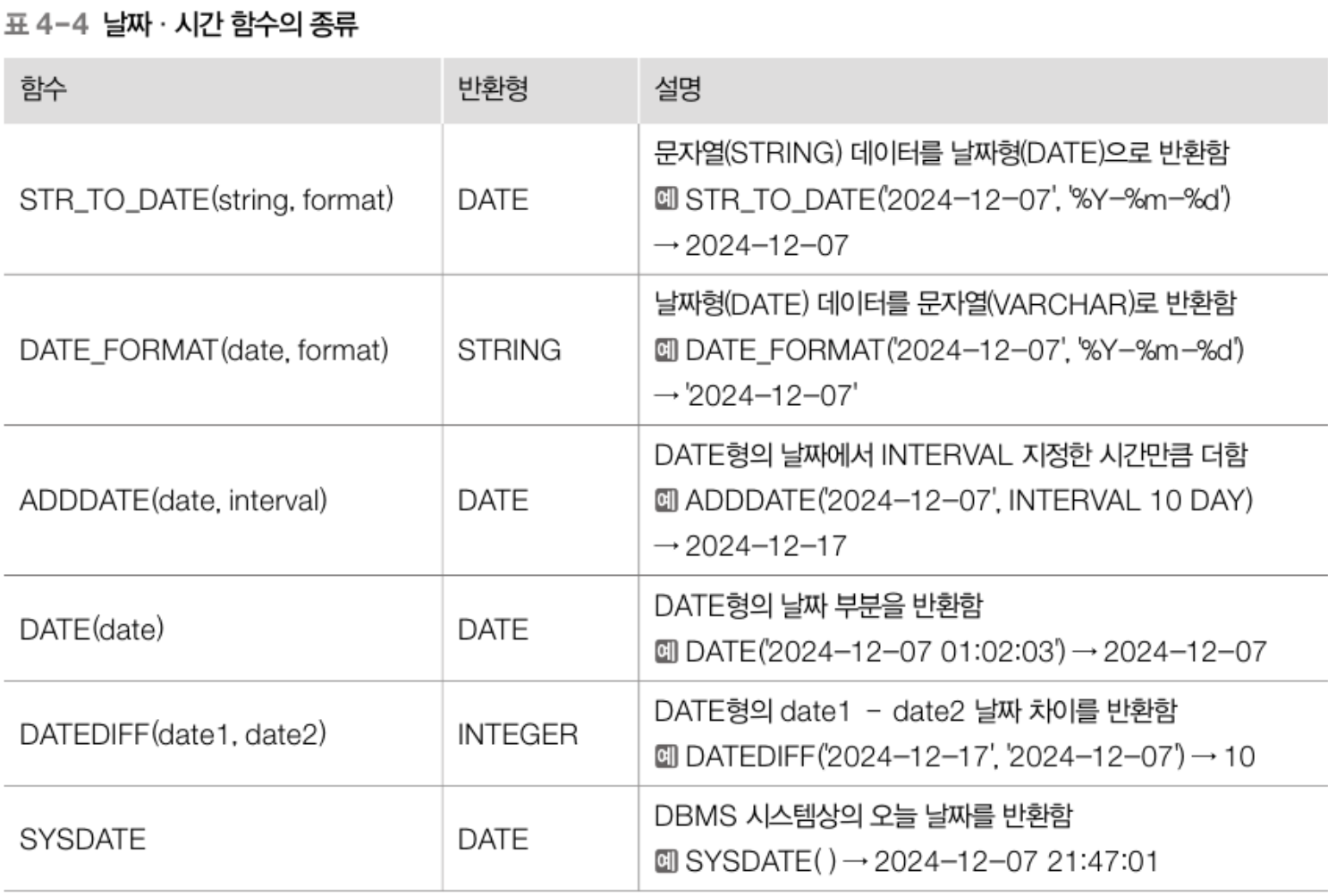
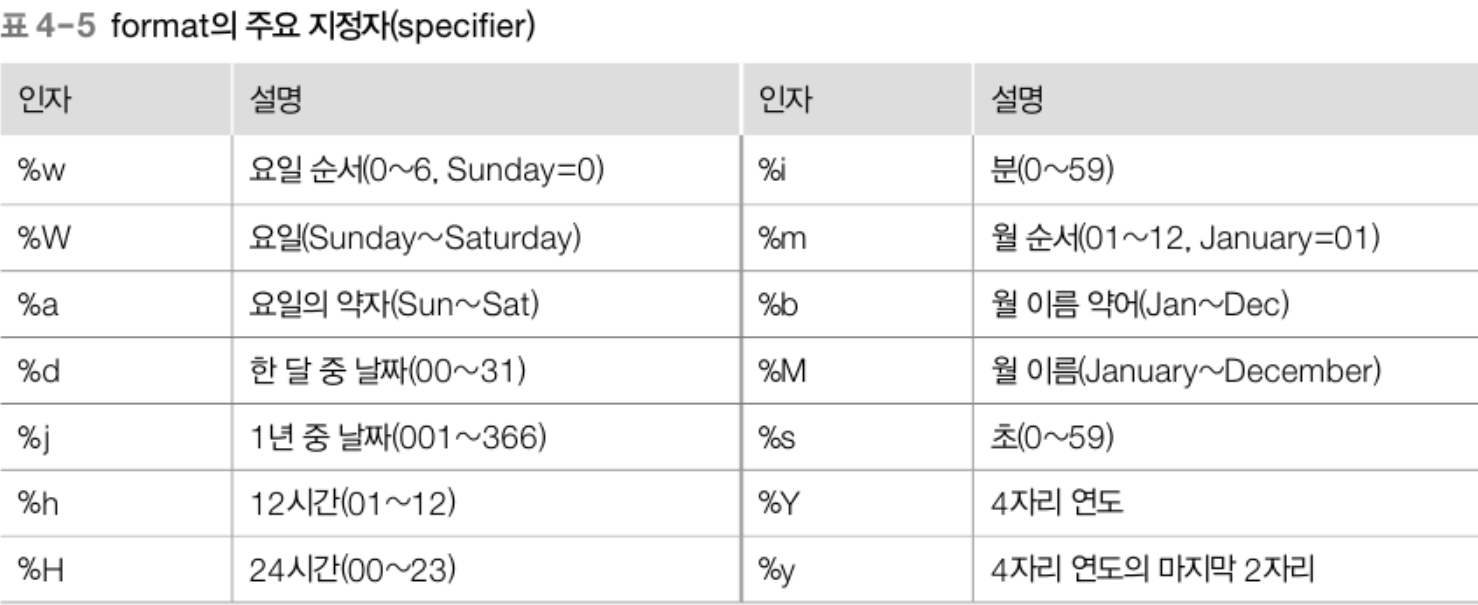
9. NULL 처리
# NULL 값 처리가 필요한 이유
- NULL이란 값이 비어있다는 건데, 연산 시 의도치않은 결과를 만드는 주범임
- NULL 값에 대한 연산과 집계 함수 특징을 보면 알 수 있음
ㄴ NULL + 숫자 = NULL
ㄴ 집계함수(SUM, AVG, COUNT, ...) 계산 시 NULL이 포함된 행은 집계에서 제외됨
ㄴ 해당되는 행이 하나도 없을 경우 SUM, AVG 결과는 NULL, COUNT는 0이 됨

# NULL 처리하기
- NULL을 그냥 둘 순 없으니 NULL인지 확인 후 값을 대체하든 뭐든 해야됨
- NULL값 확인은 IS NULL, IS NOT NULL 사용 (NULL과 공백은 다르다 명심해라)
- NULL값을 다른 값으로 대체할 땐 IFNULL 함수를 사용
- Q1. 고객의 이름, 전화번호를 나타내되 전화번호가 없는 경우 '연락처 없음'으로 표기하시오
SELECT name'이름', IFNULL(phone, '연락처없음') '전화번호' FROM customer; 박지성 000-5000-0001 김연아 000-6000-0001 김연경 000-7000-0001 추신수 000-8000-0001 박세리 연락처없음
# 변수 사용하기
- MySQL도 응용프로그램처럼 변수 사용이 가능함
- 변수를 활용하면 행번호를 붙이기나 이런 저런 작업이 가능
- 방법은 변수 이름엔 @ 기호를, 치환문에는 SET과 := 기호를 쓰면됨 (Spring에서 본 그거 맞음)
SET @seq:=0; SELECT (@seq:=@seq+1) '순번', custid, name FROM Customer WHERE @seq < 3; 순번 custid name 1 1 박지성 2 2 김연아 3 3 김연경
10. 부속질의
# 부속질의 왜 씀?
- 부속질의란 하나의 SQL 문 안에 다른 SQL 문이 중첩된 질의
- 주로 메인 쿼리의 조건에 활용하기 위해 사용
- 경우에 따라선 조인을 대체하기도 함 (데이터가 대량일 경우. 모두 합쳐 연산하는 조인보다 성능이 좋기 때문에)

# 부속질의 분류 및 용어정리
- 부속질의는 위치와 역할에 따라 WHERE / SELECT / FROM 부속질의로 분류함
- 그리고 실무에선 이들 각각을 중첩질의 / 스칼라 부속질의 / 인라인 뷰 라고 부름

- 경우에 따라선 동작 방식과 반환결과 형태에 따라 분류하기도 함
ㄴ 동작 방식기준 : 상관 부속질의(주질의의 값을 상속받음), 비상관 부속질의(주질의랑 독립됨)
ㄴ 반환결과 형태 : 단일행 부속질의(부속질의 결과=1행), 다중행 부속질의(부속질의 결과=여러 행)
# 중첩 질의 (WHERE 부속질의)
- WHERE 절에서 사용되는 부속질의
- Q1. 평균 주문금액 이하의 줌누에 대해 주문번호와 금액을 나타낸시오 (비교연산자)
SELECT orderid '주문번호', saleprice '금액' FROM orders WHERE saleprice <= (SELECT AVG(saleprice) FROM orders); /* 주문번호 금액 1 6000 3 8000 4 6000 9 7000 */ - Q2. 각 고객의 평균 주문금액보다 큰 금액의 주문 내역에 대해 주문번호, 고객번호, 금액을 나타내시오 (비교연산자)
SELECT orderid '주문번호', custid '고객번호', saleprice '금액' FROM orders o1 WHERE saleprice > (SELECT AVG(saleprice) FROM orders o2 WHERE o1.custid=o2.custid); /* 주문번호 고객번호 금액 2 1 21000 3 2 8000 5 4 20000 8 3 12000 10 3 13000 */ - Q3. 대만민국에 거주하는 고객에게 판매한 도서의 총 판매액을 구하시오 (집합 연산자 IN / NOT IN)
SELECT SUM(saleprice) '총판매액' FROM orders WHERE custid IN (SELECT custid FROM customer WHERE address LIKE '%대한민국%'); /* 총판매액 46000 */ - Q4. 3번 고객이 주문한 도서의 최고 금액보다 더 비싼 도서를 구입한 주문의 주문번호와 판매금액을 보이시오 (한정 연산자 ALL, SOME/ANY)
SELECT orderid '주문번호', saleprice '판매금액' FROM orders WHERE saleprice > ALL (SELECT saleprice FROM orders WHERE custid=3); /* 주문번호 판매금액 2 21000 5 20000 */ - Q5. 대한민국에 거주하는 고객에게 판매한 도서의 총판매액을 구하시오
SELECT SUM(saleprice) '총판매액' FROM orders o WHERE EXISTS (SELECT * FROM customer c WHERE address LIKE '%대한민국%' AND o.custid=c.custid); /* 총판매액 46000 */
# 스칼라 부속질의 (SELECT 부속질의)
- SELECT 절에서 사용되는 부속질의
- 부속질의 결과값이 단일행 & 단일열을 반환하는 스칼라 값임
- 의외로 UPDATE 문의 벌크연산에도 사용됨

- Q1. 고객별 판매액을 나타내시오(고객이름과 고객별 판매액 출력)
SELECT (SELECT name FROM customer c WHERE c.custid=o.custid) 'name', SUM(saleprice) 'total' FROM orders o GROUP BY o.custid; /* 박지성 39000 김연아 15000 김연경 31000 추신수 33000 */
- 결과를 보면 단일 행이 아닌데 어떻게 스칼라 부속질의가 단일행 & 단일열을 반환하는지 의문이 들 수 있음
- 그 이유는 다음과 같은 과정을 거치기 때문
[1] 부속질의에서 custid (유일 값)를 기준으로 결과를 가져옴 (딘일 행)
[2] 그중 name 속성값만 가져옴 (단일 열)
[3] 따라서 custid=1인 고객이름(name) 1개 (딘일행&단일열) 반환
[4] 그 다음 custid=2인 고객에 대해서도 똑같은 과정 수행 (단일행&단일열) 반환
[5] 그걸 주질의에선 하나씩 엮어서 결과로 표출

- Q2. Orders 테이블에 각 주문에 맞는 도서이름을 입력하시오 (ALTER & Bulk 연산)
ALTER TABLE Orders ADD bname VARCHAR(40); -- bname 컬럼 신규추가 UPDATE Orders o SET bname = (SELECT bookname FROM book b WHERE o.bookid=b.bookid); /* 1 1 1 6000 2024-07-01 축구의 역사 2 1 3 21000 2024-07-03 축구의 이해 3 2 5 8000 2024-07-03 피겨 교본 4 3 6 6000 2024-07-04 배구 단계별기술 5 4 7 20000 2024-07-05 야구의 추억 ...*/
# 인라인 뷰 (FROM 부속질의)
- FROM 절에서 사용되는 부속질의
- 부속질의 결과값이 다중 행, 다중 열이어도 상관없음
- 이름이 인라인 뷰인 이유는 일시적으로 생성된 가상의 테이블(=뷰)을 사용하기 때문
- Q1. 고객번호가 2 이하인 고객의 판매액을 나타내시오 (고객이름, 고객별 판매액 출력)
SELECT c.name '고객명', SUM(o.saleprice) '판매액' FROM Orders o, (SELECT custid, name FROM customer WHERE custid<=2) c WHERE o.custid=c.custid GROUP BY c.name; /* 박지성 39000 김연아 15000 */
11. 뷰
# 뷰(View)란?
- 하나 이상의 테이블을 합쳐 만든 가상의 테이블
- 가상이지만 실제 테이블처럼 사용할 수 있도록 만든 데이터베이스 개체임
ㄴ 물론 일부 작업 수행에 제약이 있긴함 - 다만 실제 데이터는 아니므로 데이터를 디스크에 저장하진 않음
- 대신 DBMS에 뷰 생성문만 저장해두고 나중에 해당 정의를 참조해 질의를 수행하는 방식임

# 뷰 왜씀?
- 재사용 & 편리성 : 자주 사용되는 질의를 뷰로 미리 정의해두면 재사용성과 편리성이 올라감
- 보안성 : 사용자별로 접근가능한 데이터를 선별해 뷰로 만들어두고 보여줄 수 있음
- 독립성 : 원본 테이블 구조가 변경돼도 영향을 주지 않도록 논리적 독립성을 얻을 수 있음
12. 뷰 생성 및 수정/삭제
# 뷰 생성하기
- 기본 문법
CREATE VIEW 뷰이름 [(열이름1, 열이름2, ...)] AS SELECT - Q1. 도서 이름에 '축구'가 포함되는 자료를 담은 뷰를 생성하시오
CREATE VIEW vw_book AS SELECT * FROM book WHERER bookname LIKE '%축구%'; - Q2. 주소에 '대한민국'을 포함하는 고객들로 구성된 뷰를 생성하시오
CREATE VIEW vw_customer AS SELECT * FROM customer WHERE address LIKE '%대한민국%'; - Q3. Orders 테이블에서 고객이름과 도서이름을 바로 확인할 수 있는 뷰를 생성한 후, '김연아' 고객이 구입한 도서의 주문번호, 도서이름, 주문액을 나타내시오
CREATE VIEW vw_orders (orderid, custid, name, bookid, bookname, saleprice, orderdate) AS SELECT o.orderid, o.custid, c.name, o.bookid, b.bookname, o.saleprice, o.orderdate FROM orders o, customer c, book b WHERE o.custid=c.custid AND o.bookid=b.bookid; SELECT orderid, bookname, saleprice FROM vw_orders WHERE name='김연아'; /* orderid bookname saleprice 3 피겨 교본 8000 9 Olympic Champions 7000 */
# 뷰 수정/삭제하기
- 뷰도 기존 테이블처럼 수정/삭제가 가능함 (물론 일부 내용에서 제한이 있긴 하지만)
--뷰 수정하기 CREATE OR REPLACE VIEW 뷰이름 [(열이름1, 열이름2, ...)]; --뷰 삭제하기 DROP VIEW 뷰이름 [, ...n]; - Q1. 앞서 생성한 vw_customer 뷰를 영국을 주소로 가진 고객으로 변경하시오. 추가로 phone 속성은 불필요하므로 생략하시오.
CREATE OR REPLACE VIEW vw_customer (custid, name, address) AS SELECT custid, name, address FROM customer WHERE address LIKE '%영국%'; - Q2. 앞서 생성한 vw_customer 뷰를 삭제하시오
DROP VIEW vw_customer;
# 시스템 뷰
- MySQL을 포함한 모든 DBMS가 기본으로 제공하는 특별한 뷰
- DB개체 (테이블, 함수, 뷰, ...)나 시스템 통계 정보 등을 확인하기 위해 제공됨
- 시스템 뷰를 데이터 딕셔너리 뷰 or 시스템 카탈로그 라고도 부름
- 사용자는 시스템 뷰를 참조하면서 DB 튜닝이나 기타 문제들을 해결함
- MySQL의 경우 INFORMATION_SCHEMA 데이터베이스에 저장돼있음

